LangChain
언어모델을 보다 간편하게 사용할 수 있게해주는 프레임워크.
공식 사이트
https://python.langchain.com/docs/introduction/
Introduction | 🦜️🔗 LangChain
LangChain is a framework for developing applications powered by large language models (LLMs).
python.langchain.com
RAG( Retrieval-Augmented Generation )
한글로 검색 증강 생성으로 RAG를 사용하지 않는 LLM은 오답(할루시네이션)을 만들어낼 확률이 높으며 이를 해결하기위해 RAG를 사용
RAG는 답변을 생성할 시 답변 생성에 도움이 되는 소스 데이터를 함께 LLM에 전달함으로써 할루시네이션을 줄인다.
RAG의 순서
1. 검색할 데이터를 추출한다.
증강 검색할 데이터를 워드파일로부터 추출한다.
2. 데이터를 파싱한다.
해당 데이터를 chunk 단위로 분할한다. 이는 LLM이 토큰 단위로 데이터를 처리하며 입력가능한 토큰의 개수는 정해져 있고 불필요한 데이터를 너무 많이 넘기게 되면 RAG 성능이 낮아짐
3. 데이터를 임베딩 한다.
데이터를 벡터의 형태로 변환한다. 벡터로 변환하므로서 각 단어들간의 유사도를 유추 할 수 있으므로 입력한 단어와 높은 유사도를 가지는 데이터를 검색한다.
4. DB에 적재한다.
5. 검색 시 유사도가 높은 데이터를 추출한다.
질문을 임베딩 하여 벡터화 하고 해당 벡터와 유사도가 높은 데이터를 찾는다.
6. 해당 데이터와 질문을 프롬프트로 만들어 LLM에 질문한다.
유사도가 높은 데이터를 사용하여 문장 답변을 생성한다.
LangChain 및 필요 라이브러리 설치
%pip install --upgrade pip
%pip install langchain-community docx2txt langchain_text_splitters python-dotenv langchain-openai langchain-chroma
langchain-community: LangChain의 인터페이스
langchain-openai: 인터페이스로 사용할 내부 코어
docx2txt : 워드 추출 라이브러리
langchain-text-splitters: 문장 파서

openAI, Ollama anthropic 등 다양한 LLM을 사용할수 있다.
Langchain을 사용하여 문장 생성
from langchain.chat_models import ChatOpenAI
api_key='api 키'
model = 'gpt-4o-mini'
llm = ChatOpenAI(api_key=api_key, model=model)
llm.invoke("안녕 반가워")
Docx2txt를 사용한 워드 파일 데이터 추출
from langchain_community.document_loaders import Docx2txtLoader
loader = Docx2txtLoader('../tax_with_table.docx')
document = loader.load()
document
TextSplitter를 사용한 워드 파일 분할
파일을 분할하는 이유
- 입력할 수 있는 토큰의 수가 정해져 있기 때문에 무한정 큰 데이터를 입력 할 수 없음
- 유사도 검색으로 검색 된 결과가 너무 크다면 불필요한 정보까지 함께 입력 되기 때문에 정확성이 낮아 질 수 있음
- overlap: 이전 문장의 문맥을 이해하기 위해 이전 청크의 일부분을 가져오는 크기
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000
, chunk_overlap = 100
)
loader.load_and_split(text_splitter=text_splitter)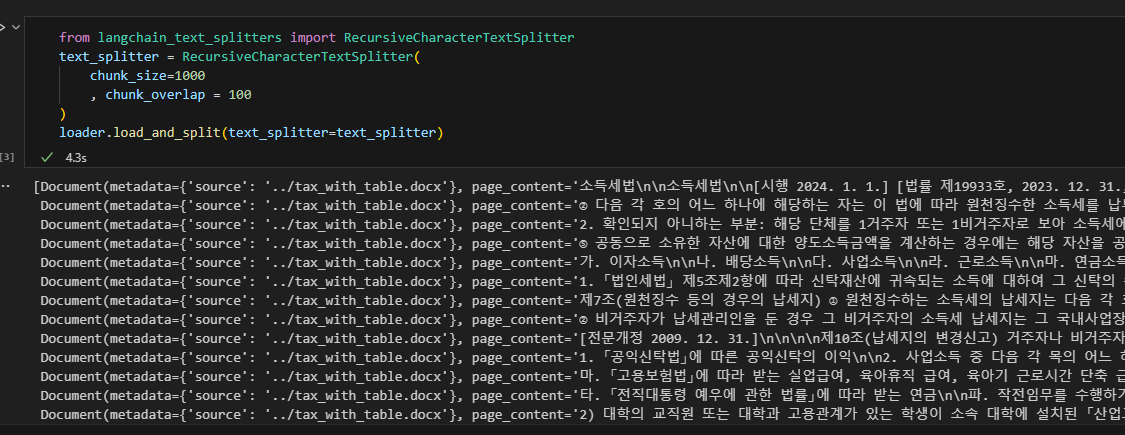
RecursiveCharacterTextSplitter 외에도 여러 splitter가 존재한다.
임베딩
문자를 vector화 하는 과정
from langchain_community.embeddings import OpenAIEmbeddings
embedding = OpenAIEmbeddings(model='text-embedding-3-small')
embedding_document = embedding.embed_documents(["안녕하세요", "반가워요"])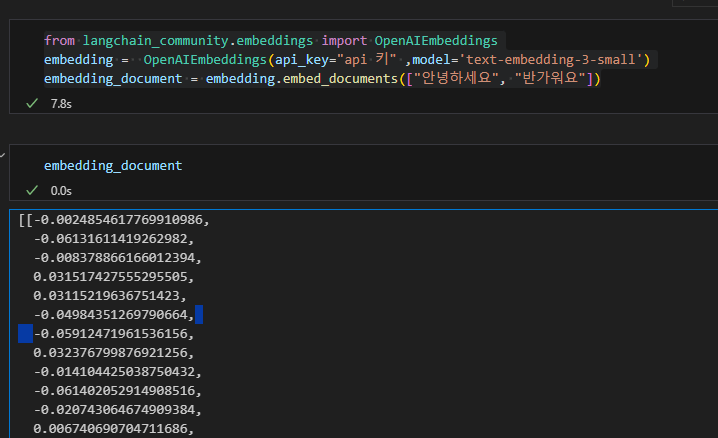
데이터 적재
VectorDB는 Chroma, Pinecone등이 존재하며 해당 DB마다 사용하고 있는 검색 알고리즘이 다르다.
이번 테스트에서는 Chroma를 사용한다.
Chroma는 메모리 DB로 간단히 사용할수 있으며 파일로 데이터를 저장할 수 있다.
from langchain_community.embeddings import OpenAIEmbeddings
from dotenv import load_dotenv
from langchain_community.vectorstores import Chroma
#.env 파일에 OPENAI_API_KEY=api key 추가
load_dotenv()
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
store = Chroma.from_documents(collection_name="tax_document", persist_directory="../Chroma", documents=splitted_document, embedding=embedding)
# 파일에서 받아 올 때
# store = Chroma(collection_name="tax_document", persist_directory="../Chroma", embedding_function=embedding)
VectorStore에 쿼리 전송
query ="연봉 3000만원의 소득세"
# 유사도 높은 3개의 결과 반환
result = store.similarity_search_with_score(query=query, k=3)
Prompt생성
https://smith.langchain.com/hub/
LangSmith
smith.langchain.com
langchaing hub에는 다른 사용자들이 만들어둔 prompt들이 존재한다.
직접 prompt를 만들지 않아도 다양한 prompt를 사용할 수 있다. 다만 API로 pull을 사용할 시 API_KEY를 발급 받아야한다. 간단하게 검색하여 template으로 사용하기로 한다.
from langchain_community.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
# API KEY를 받아서 사용할 시
# from langchain import hub
# prompt = hub.pull("rlm/rag-prompt")
prompt_text =""""
"You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:"""
prompt = PromptTemplate.from_template(prompt_text)
Chain
위의 Prompt, llm, VectorStore를 합친 인터페이스로 Chain이 없다면 로직은 아래와 같아진다.
1. 질문들 받는다
2. 질문을 retriver(Store)로부터 유사도 높은 Context(문서)를 추출한다.
3. prompt에 context와 질문을 을 매핑한다.
4. llm에 질문한다.
Chain의 생성자로 prompt, llm, VectorStore를 전달하기 때문에 신규 질문이 들어오면 chain.invoke("질문")만 사용하면된다.
Chain은 종류
이번에는 RerivalQA라는 chain을 사용한다.
이 체인은 먼저 관련 문서를 가져오기 위한 검색 단계를 수행한 다음, 해당 문서를 LLM에 전달하여 응답을 생성한다.
그외 키워드 추출 등 다양한 chain들이 존재한다.
https://python.langchain.com/v0.1/docs/modules/chains/
How to migrate from v0.0 chains | 🦜️🔗 LangChain
LangChain has evolved since its initial release, and many of the original "Chain" classes
python.langchain.com
from langchain.chains import RetrievalQA
from langchain_community.chat_models import ChatOpenAI
api_key='api key'
model = 'gpt-4o-mini'
llm = ChatOpenAI(api_key=api_key, model=model)
chain = RetrievalQA.from_chain_type(
llm,
retriever=store.as_retriever(),
chain_type_kwargs={"prompt": prompt}
)
chain.invoke(query)

'AI????, LLM???' 카테고리의 다른 글
| Langchain의 AgentType (2) | 2025.05.09 |
|---|---|
| AI Agent와 Tool 2 (langchain을 사용한) (0) | 2025.04.15 |
| AI Agent와 Tool 1 (Python을 사용한 간단한 AI Agnet 만들기) (1) | 2025.04.15 |